 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsymmetric Generative Recommendation via Multi-Expert Projection and Multi-Faceted Hierarchical Quantization
May 14, 2026Generative Recommendation (GenRec) models reformulate recommendation as a sequence generation task, representing items as discrete Semantic IDs used symmetrically as both inputs and prediction targets. We identify a critical dual-stage information bottleneck in this design: (1) the Input Bottleneck, where lossy quantization degrades fine-grained semantics, while popularity bias skews the learned representations toward frequent items, and (2) the Output Bottleneck, where imprecise discrete targets limit supervision quality. To address these issues, we propose AsymRec, an asymmetric continuous-discrete framework that decouples input and output representations. Specifically, Multi-expert Semantic Projection (MSP) maps continuous embeddings into the Transformer's hidden space via expert-specialized projections, preserving semantic richness and improving generalization to infrequent items. Multi-faceted Hierarchical Quantization (MHQ) constructs high-capacity, structured discrete targets through multi-view and multi-level quantization with semantic regularization, preventing dimensional collapse while retaining fine-grained distinctions. Extensive experiments demonstrate that AsymRec consistently outperforms state-of-the-art generative recommenders by an average of 15.8 %. The code will be released.
FEDIN: Frequency-Enhanced Deep Interest Network for Click-Through Rate Prediction
May 03, 2026Sequential recommendation models often struggle to capture latent periodic patterns in user interests, primarily due to the noise inherent in time-domain behavioral data. While frequency-domain analysis offers a global perspective to address this, existing approaches typically treat user sequences in isolation, overlooking the crucial context of the target item. In this work, we present a novel empirical observation: user attention scores exhibit distinct spectral entropy distributions when conditioned on positive versus negative target items. Specifically, true user interests manifest as highly concentrated spectral patterns with lower entropy in the frequency domain, whereas irrelevant behaviors appear as high-entropy noise. Leveraging this insight, we propose the Frequency-Enhanced Deep Interest Network (FEDIN). FEDIN introduces a frequency-domain branch that utilizes a target-aware spectrum filtering mechanism to isolate these periodic interest signals. Extensive experiments on three public datasets demonstrate that FEDIN consistently outperforms state-of-the-art sequential recommendation baselines, demonstrating superior robustness against noise. We have released our code at: https://github.com/otokoneko/FEDIN.
RankUp: Towards High-rank Representations for Large Scale Advertising Recommender Systems
Apr 21, 2026The scaling laws for recommender systems have been increasingly validated, where MetaFormer-based architectures consistently benefit from increased model depth, hidden dimensionality, and user behavior sequence length. However, whether representation capacity scales proportionally with parameter growth remains largely unexplored. Prior studies on RankMixer reveal that the effective rank of token representations exhibits a damped oscillatory trajectory across layers, failing to increase consistently with depth and even degrading in deeper layers. Motivated by this observation, we propose \textbf{RankUp}, an architecture designed to mitigate representation collapse and enhance expressive capacity through randomized permutation splitting over sparse features, a multi-embedding paradigm, global token integration, crossed pretrained embedding tokens and task-specific token decoupling. RankUp has been fully deployed in large-scale production across Weixin Video Accounts, Official Accounts and Moments, yielding GMV improvements of 3.41\%, 4.81\% and 2.21\%, respectively.
TokenFormer: Unify the Multi-Field and Sequential Recommendation Worlds
Apr 15, 2026Recommender systems have historically developed along two largely independent paradigms: feature interaction models for modeling correlations among multi-field categorical features, and sequential models for capturing user behavior dynamics from historical interaction sequences. Although recent trends attempt to bridge these paradigms within shared backbones, we empirically reveal that naive unifying these two branches may lead to a failure mode of Sequential Collapse Propagation (SCP). That is, the interaction with those dimensionally ill non-sequence fields leads to the dimensional collapse of the sequence features. To overcome this challenge, we propose TokenFormer, a unified recommendation architecture with the following innovations. First, we introduce a Bottom-Full-Top-Sliding (BFTS) attention scheme, which applies full self-attention in the lower layers and shrinking-window sliding attention in the upper layers. Second, we introduce a Non-Linear Interaction Representation (NLIR) that applies one-sided non-linear multiplicative transformations to the hidden states. Extensive experiments on public benchmarks and Tencent's advertising platform demonstrate state-of-the-art performance, while detailed analysis confirm that TokenFormer significantly improves dimensional robustness and representation discriminability under unified modeling.
Tencent Advertising Algorithm Challenge 2025: All-Modality Generative Recommendation
Apr 04, 2026Generative recommender systems are rapidly emerging as a new paradigm for recommendation, where collaborative identifiers and/or multi-modal content are mapped into discrete token spaces and user behavior is modelled with autoregressive sequence models. Despite progress on multi-modal recommendation datasets, there is still a lack of public benchmarks that jointly offer large-scale, realistic and fully all-modality data designed specifically for generative recommendation (GR) in industrial advertising. To foster research in this direction, we organised the Tencent Advertising Algorithm Challenge 2025, a global competition built on top of two all-modality datasets for GR: TencentGR-1M and TencentGR-10M. Both datasets are constructed from real de-identified Tencent Ads logs and contain rich collaborative IDs and multi-modal representations extracted with state-of-the-art embedding models. The preliminary track (TencentGR-1M) provides 1 million user sequences with up to 100 interacted items each, where each interaction is labeled with exposure and click signals, while the final track (TencentGR-10M) scales this to 10 million users and explicitly distinguishes between click and conversion events at both the sequence and target level. This paper presents the task definition, data construction process, feature schema, baseline GR model, evaluation protocol, and key findings from top-ranked and award-winning solutions. Our datasets focus on multi-modal sequence generation in an advertising setting and introduce weighted evaluation for high-value conversion events. We release our datasets at https://huggingface.co/datasets/TAAC2025 and baseline implementations at https://github.com/TencentAdvertisingAlgorithmCompetition/baseline_2025 to enable future research on all-modality generative recommendation at an industrial scale. The official website is https://algo.qq.com/2025.
From Feature Interaction to Feature Generation: A Generative Paradigm of CTR Prediction Models
Dec 16, 2025



Click-Through Rate (CTR) prediction, a core task in recommendation systems, aims to estimate the probability of users clicking on items. Existing models predominantly follow a discriminative paradigm, which relies heavily on explicit interactions between raw ID embeddings. However, this paradigm inherently renders them susceptible to two critical issues: embedding dimensional collapse and information redundancy, stemming from the over-reliance on feature interactions \emph{over raw ID embeddings}. To address these limitations, we propose a novel \emph{Supervised Feature Generation (SFG)} framework, \emph{shifting the paradigm from discriminative ``feature interaction" to generative ``feature generation"}. Specifically, SFG comprises two key components: an \emph{Encoder} that constructs hidden embeddings for each feature, and a \emph{Decoder} tasked with regenerating the feature embeddings of all features from these hidden representations. Unlike existing generative approaches that adopt self-supervised losses, we introduce a supervised loss to utilize the supervised signal, \ie, click or not, in the CTR prediction task. This framework exhibits strong generalizability: it can be seamlessly integrated with most existing CTR models, reformulating them under the generative paradigm. Extensive experiments demonstrate that SFG consistently mitigates embedding collapse and reduces information redundancy, while yielding substantial performance gains across various datasets and base models. The code is available at https://github.com/USTC-StarTeam/GE4Rec.
Large Foundation Model for Ads Recommendation
Aug 20, 2025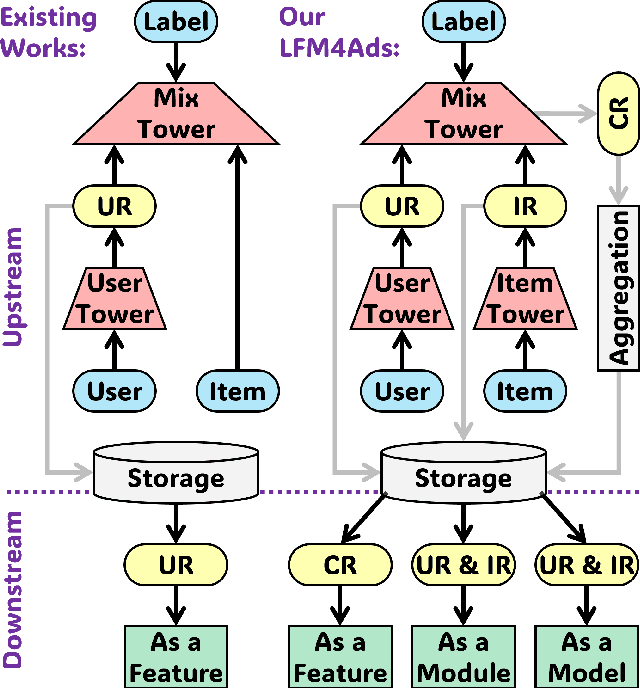
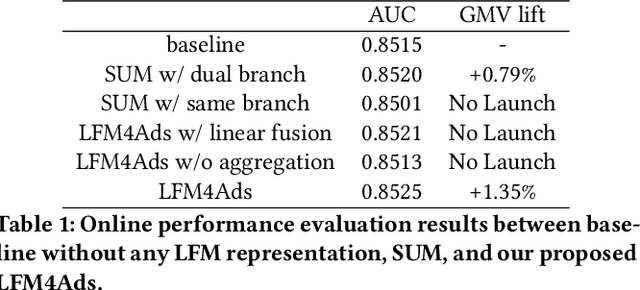
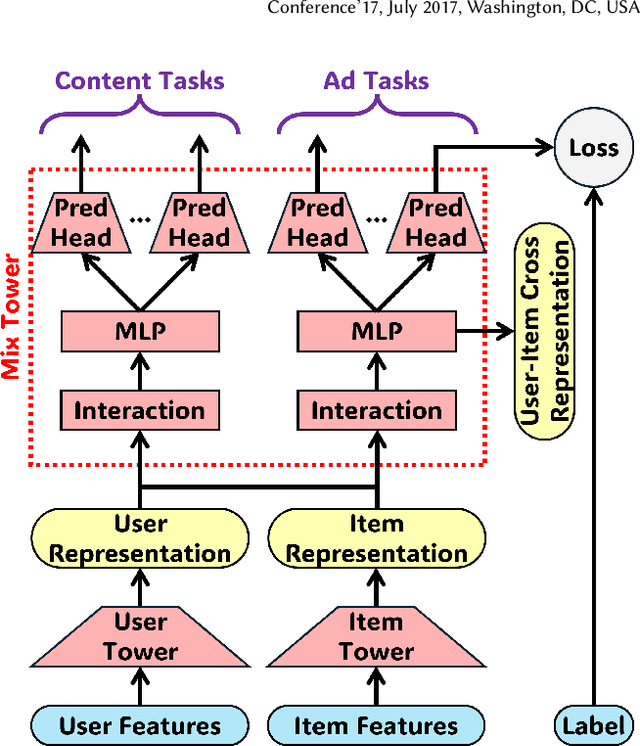
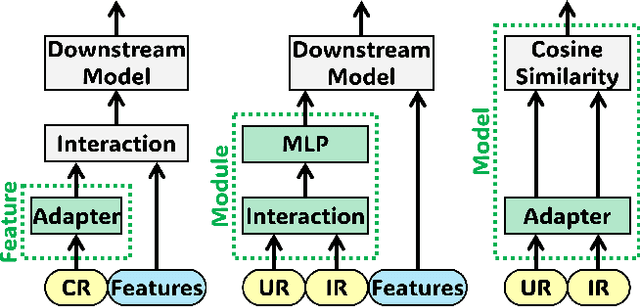
Online advertising relies on accurate recommendation models, with recent advances using pre-trained large-scale foundation models (LFMs) to capture users' general interests across multiple scenarios and tasks. However, existing methods have critical limitations: they extract and transfer only user representations (URs), ignoring valuable item representations (IRs) and user-item cross representations (CRs); and they simply use a UR as a feature in downstream applications, which fails to bridge upstream-downstream gaps and overlooks more transfer granularities. In this paper, we propose LFM4Ads, an All-Representation Multi-Granularity transfer framework for ads recommendation. It first comprehensively transfers URs, IRs, and CRs, i.e., all available representations in the pre-trained foundation model. To effectively utilize the CRs, it identifies the optimal extraction layer and aggregates them into transferable coarse-grained forms. Furthermore, we enhance the transferability via multi-granularity mechanisms: non-linear adapters for feature-level transfer, an Isomorphic Interaction Module for module-level transfer, and Standalone Retrieval for model-level transfer. LFM4Ads has been successfully deployed in Tencent's industrial-scale advertising platform, processing tens of billions of daily samples while maintaining terabyte-scale model parameters with billions of sparse embedding keys across approximately two thousand features. Since its production deployment in Q4 2024, LFM4Ads has achieved 10+ successful production launches across various advertising scenarios, including primary ones like Weixin Moments and Channels. These launches achieve an overall GMV lift of 2.45% across the entire platform, translating to estimated annual revenue increases in the hundreds of millions of dollars.
Enhancing CTR Prediction with De-correlated Expert Networks
May 23, 2025Modeling feature interactions is essential for accurate click-through rate (CTR) prediction in advertising systems. Recent studies have adopted the Mixture-of-Experts (MoE) approach to improve performance by ensembling multiple feature interaction experts. These studies employ various strategies, such as learning independent embedding tables for each expert or utilizing heterogeneous expert architectures, to differentiate the experts, which we refer to expert \emph{de-correlation}. However, it remains unclear whether these strategies effectively achieve de-correlated experts. To address this, we propose a De-Correlated MoE (D-MoE) framework, which introduces a Cross-Expert De-Correlation loss to minimize expert correlations.Additionally, we propose a novel metric, termed Cross-Expert Correlation, to quantitatively evaluate the expert de-correlation degree. Based on this metric, we identify a key finding for MoE framework design: \emph{different de-correlation strategies are mutually compatible, and progressively employing them leads to reduced correlation and enhanced performance}.Extensive experiments have been conducted to validate the effectiveness of D-MoE and the de-correlation principle. Moreover, online A/B testing on Tencent's advertising platforms demonstrates that D-MoE achieves a significant 1.19\% Gross Merchandise Volume (GMV) lift compared to the Multi-Embedding MoE baseline.
Pre-train, Align, and Disentangle: Empowering Sequential Recommendation with Large Language Models
Dec 05, 2024Sequential recommendation (SR) aims to model the sequential dependencies in users' historical interactions to better capture their evolving interests. However, existing SR approaches primarily rely on collaborative data, which leads to limitations such as the cold-start problem and sub-optimal performance. Meanwhile, despite the success of large language models (LLMs), their application in industrial recommender systems is hindered by high inference latency, inability to capture all distribution statistics, and catastrophic forgetting. To this end, we propose a novel Pre-train, Align, and Disentangle (PAD) paradigm to empower recommendation models with LLMs. Specifically, we first pre-train both the SR and LLM models to get collaborative and textual embeddings. Next, a characteristic recommendation-anchored alignment loss is proposed using multi-kernel maximum mean discrepancy with Gaussian kernels. Finally, a triple-experts architecture, consisting aligned and modality-specific experts with disentangled embeddings, is fine-tuned in a frequency-aware manner. Experiments conducted on three public datasets demonstrate the effectiveness of PAD, showing significant improvements and compatibility with various SR backbone models, especially on cold items. The implementation code and datasets will be publicly available.
Towards Unifying Feature Interaction Models for Click-Through Rate Prediction
Nov 19, 2024



Modeling feature interactions plays a crucial role in accurately predicting click-through rates (CTR) in advertising systems. To capture the intricate patterns of interaction, many existing models employ matrix-factorization techniques to represent features as lower-dimensional embedding vectors, enabling the modeling of interactions as products between these embeddings. In this paper, we propose a general framework called IPA to systematically unify these models. Our framework comprises three key components: the Interaction Function, which facilitates feature interaction; the Layer Pooling, which constructs higher-level interaction layers; and the Layer Aggregator, which combines the outputs of all layers to serve as input for the subsequent classifier. We demonstrate that most existing models can be categorized within our framework by making specific choices for these three components. Through extensive experiments and a dimensional collapse analysis, we evaluate the performance of these choices. Furthermore, by leveraging the most powerful components within our framework, we introduce a novel model that achieves competitive results compared to state-of-the-art CTR models. PFL gets significant GMV lift during online A/B test in Tencent's advertising platform and has been deployed as the production model in several primary scenarios.